politwoops.tw 進度規劃現況
這是 watchOut x g0v summer code project.
後端 fork from https://github.com/sunlightlabs/politwoops-tweet-collector
前端 fork from https://github.com/sunlightlabs/politwoops
後端是主要進度。
lanfon FB explorer 、 Python's faceboook-sdk
github repo: feepy、twpolitwoops-collector
先 fork fb-sdk 下來改
預計進度
- 把 politwoops.tw 整個架起來
- 建後端的 collector
- 做資料測試
- 修 mockup and web 介面
進度現況
The 2nd part.
- 做個簡單的 web 介面 to show data.
- 實做 screenshot-worker 功能
- 建前端 ( politwoops' rails )
- additional:
不部會的新聞稿 RSS collector.
Ref: http://logbot.g0v.tw/channel/g0v.tw/2014-08-21#18
星期三應該可以早點到草辦(?) 討論一下第二階段的核心重點囧...
發現寫日誌↓太痛苦了只好放棄QAQ
8/7 建了專用帳號林艸艸,把公督盟的立委 FB、專頁 資訊都 follow 完成並取得 uid.
8/6 先把 feed_stream 套回 -client, 並修正 -work, 讓 -client 讀到的資料可以被 -work 存取。
待解 issues:
**改記錄在github上。
(以下廢棄-_-)
- Client
- FB access_token expire
- 增加其他政治人物資料(eg. 市長) in 市長候選人
- streaming.py 的 access exception handle. ( set retry )
- access_token extend, should rewrite into .ini
- retry time should be slowly
- exceed rate call.
- Worker
先改成 30s
error #613 , request 太頻繁的樣子 囧rz...
re-request 改成 90s... 但還是會 err 613 (sometimes)
- Checker
- check feed should separate by time.
這個要先解... api 限制 600 calls / 600 seconds,所以要均分 10 mins 下來的總 calls 數量。
(( 可能的解法也許是壓下 per check tick 的 feeds 數量, 壓在 500 feeds/ 600secs 以下,留 100 calls 給 streaming request
避免超額的問題,先改成 check today feeds only. (8/31)
解法B: 額外建一個 api 專門拿來 check 用,不用和 client share calls/secs ((但上限仍然為 60
...*deleted_feeds 判斷有誤
might fixed.
- 當掉不會跳出...囧
- deleted_feeds 有少...(可能是cursor.execute太快 lol...)
deleted_feeds的問題猜測是 CPU 速度 > I/O... 先用 sleep a tick 測看看
solved.
- Database
- tables redesign
- feeds
- deleted_feeds
- politicians
- normal_users: id(PK, auto), user_name, facebook_id, ignored
- tmp_feeds:id(PK, feed's id), user_id, user_name, content, created, modified, feed, feed_type
- parties:id(PK, auto), name, created_at, updated_at, display_name
- offices:id(PK, auto), title, abbreviation
- pages:id(PK, auto), title, slug, content, created_at, updated_at, language
- statistics: id(PK, auto), what, when, amount, created_at, updated_at
- account_links:id(PK, auto), politician_id, link_id, created_at, updated_at
- account_types:id(PK, auto), name
- schema_migrations:version
- users
- tweet_images:id(PK, auto), url, tweet_id, created_at, updated_at
- deleted_tweets:id, user_name, content, deleted, created, modified, tweet, politician_id, approved, reviewed, reviewed_at, review_message, retweeted_id, retweeted_content, retweeted_user_name
- SQL table fields
- politicians
- tweets → feeds
deleted_tweets→ deleted_feedsedited_feeds- normal_users
- tmp_feeds
- deleted feed
streamchecker edited feed stream
↓ redisign 的重點, politicians 和 politwoops 所用的 tables 重複
↓新產生的 tables, 應該是不需要 redesign
↓「應該」不會用到的原 politwoops tables
users 應該是前端用的, 就不列出來了
↓確定不會使用的 tables
原本應該有一個 tweets 的 table, 但被我改名成 feeds 了XD... 格式和 deleted_tweets 類似
---
comments: order by desc.
- 不確定啥用的tables: users, account_links, offices, pages, statistics
- parties應該是政黨(party)的資料,tweet_images 是圖檔的儲存資料,schema_migrations 應該是tables versions(?
- feed be deleted 的驗證蠻卡的... 一般的 like post, comment post 沒辦法從 api 取得,
- 和實際被刪除的 feed 一樣會被 api return error.
- edited_feeds 需新增(但大量更新感覺資料會非常多...囧
- edited_feeds 改存在 feeds 的 feed_edited column.
- edited_feed stream 和 deleted feed stream, -worker 併在一起了。
- feed_edited 的做法寫在 talks #2.
- normal_users:
- 存一些 " found user id not in politicians " 的「一般人」或是原本取得的 politician uid 是錯的,也會先丟進這裡。had a column: ignored (被確認為一般人)
- tmp_feeds:
- 1. normal_users' feed but not be ignore.
- 2. deleted_feeds 的暫存
- 3. 其他(總之先暫存=_=
- feeds_checker:
- 目前的 idea 是每 3~5 mins 從 feeds 裡面用 id 一個一個讀(避免用 feed stream 有可能會漏掉的問題
- 但有個問題是「讀不到不見得被刪掉」=_=
=========分水嶺==========
- 把 politwoops 整個架起來(後端) #1
- 建後端的 collector //screenshot-worker 先 pass 了, so finished at week: 7/13~
- 把 collector 主要在跑的三支 .py 看懂
- tweets-client.py
- 主要進入點在 Line:158,跑兩個thread當heartbeat用(一個避免當掉),在stream_forever 裡會跑 tweepy 的 stream listener ( L:150&151)
- 核心的結構應該算是 L:60 的 class ,把 tweepy 讀到的資料 put 進 beanstalkc ,然後 alert 。 (接下來就沒它的事了XD)
- politwoops-worker.py
- 主要進入點在 Line:105,監測 beanstalk 有沒有 job ( put from tweets-client ),再做處理(L:121)。
- screenshot-worker.py
- Write a api like tweepy's on_data() //finish at week: 7/20~
- GraphAPI可以讀到:
- 自己的 wall post 出現的內容
- 讀自己的 wall post 比較近似 tweepy 的 streamListener
- 特定使用者(by id)的 feeds
- 粉絲頁的 id 可以從 data-uid 取得,但 user 的 data-id 卻不見得能夠被 api 讀取( 從chrome-> F12-> data-id )
- API 的選擇(既然要做得像 tweepy 就叫 feepy 了(X))
- write like tweepy streamListener
- 只負責讀自己的home feeds (這樣得開一個新的帳號去 follow & like politicians )
- 好處是如果被 politicians add friend 的話可以爬到 friend 級的 feed (沒被限制的話
- 壞處是 feeds 的排序...一般在看的時候可以選 top stories / most recent ,從 fb-sdk 抓下來的 data 不知道是怎麼排的。(而且資料一多的話 listener 有可能漏掉
- a politician have a listener
- 個別監聽(?)比較不會有漏訊息的問題,但 deleted feed 似乎還是無解...目前想到的做法是用 feed url 是不是導向 404 的方式去抓(但感覺頗有點難QAQ)
- uid 不易取得。而且有些 user 就算抓到了 uid ,feeds 的資料還是空的...(不知道是不是版本的問題)
這支主要是跑截圖, ly 說先不管它XD
ya 這個前面完成再來做
using faceboook-sdk
後來發現這是 v2.0 api 的問題=___= 剛改成 unversioned 就可以從 data-uid 抓到 feeds 了
=_= (((但我用自己的 data-uid 測還是不行....
這真的超詭異的... https://graph.facebook.com/{data-uid}/ 可以讀到資料,但/feed?access_token 卻 OAuth deny...
source code: feepy/facebook/streaming.py
- 目前的 usage:
- import facebook & streaming #還沒寫成module檔所以...XD
- token = '(your access_token)'
- listener = streaming.StreamListener() #politwoops 在 listener 的部份是 overriding
- stream = streaming.Stream( token, listener)
- stream.filter() #and it get run.
- Stream 功能完善化 // expect finish: 7/28~
- edited feed, add key('edited')
- deleted feed
- 套回 collector 做測試 // expect finish: 8/3~
problems:
1. exception 沒有全抓到, 有時候會 response error ( 目前是用vm測長掛,有可能是節電功能的關係XD
2. filter() 有一些參數沒寫完 (預計是要拿來做 edited & deleted 的功能, 這部份會再補上)
3. token expired 的問題 ( expired 的問題不知道何解.... 查到的大部份都是解決app's token expired, 但如果用 app 的 token 抓不到自己的 wall post. ( /v2.0/me/home/ can't request)
這部份算是 fb & twitter api 的差異, twitter 有 customer_id & secret, 但 fb 找不到 customer_id & secret....=_=
ly 說這部份可以參考 news-diff
用 async stream 實做,primary stream 1min to req ; secodary stream 5min req, to check updated_time != created_time
後來決定改第二支 -worker 的 handle_deletion。原本的刪除(因為沒 deleted key),改成讀 feeds table 再對 FB api 做個別查詢,去驗證 feed exist or not.
not here, (上週把 stream 完善一半就....跑去幫忙81了QQ)
目前打算直接把 -worker & -client rewrite 之後讓它跑看看, 原 collector repo 已 fork.
備註 & 討論
- tweepy github
核心的 library 是 tweepy 跟 beanstalk ,但 beanstalk 主要是處理資料流,最大的問題還是在 tweepy 上。
我有跑去看了一下 tweepy 的 source code ,不太確定它 streaming.listener 讀的資料是在自己的 twitter 牆上? 沒啥在用 twitter 不太理解它的運作方式....囧。
假想的情況是, api 是 listener 自己的 twitter 牆 ( twitter 是在每個 following tweet 的時候都會一併出現在 follower 的牆上吧? ),再針對 tweet 做判讀( tweet content ),所以在 on_data 的時候可以直接從 data.has_key() 裡面判斷資料.....
但現在比較實質的問題是 FB 的 api 沒有 delete 的 status, 提供的 library 也不全(昨天的 FB-pysdk 也沒有類似像 tweepy 的 api 囧,目前的情況比較可能得自幹類似的功能QQ
https://developers.facebook.com/docs/public_feed
這裡有提到facebook posts要不要參考一下?
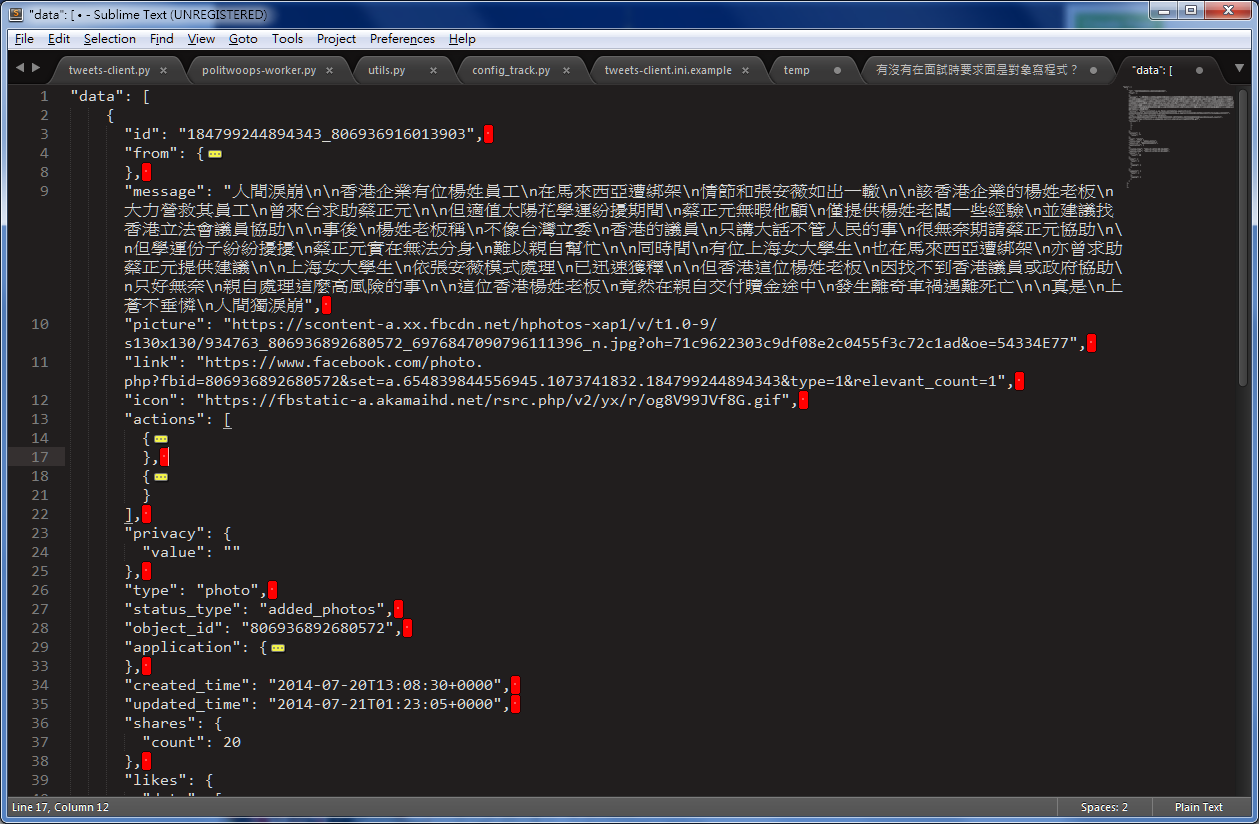
tweets-client 的資料來源是 tweepy 的 on_data funciton (讀 twitter 牆面的資料),目前找到可用的 FB Python api 只有 faceboook-sdk ...fbsdk 從 GraphAPI 讀到 FB 牆面的資料( dict 格式, keys: data, paging ),但每次讀到的資料不確定一不一樣 囧
paging 內的 previous & next 回傳的是 url (帶 accesstoken )
data 內是 list feeds,再根據每筆 feed 會有不同的 keys() 示意圖↓
- FB API 問題
post ref: https://developers.facebook.com/docs/graph-api/reference/v2.0/post/
沒有提供 edit history 可以讀
沒有提供 deleted feed 可以讀 QAQ!! (↓ 參考
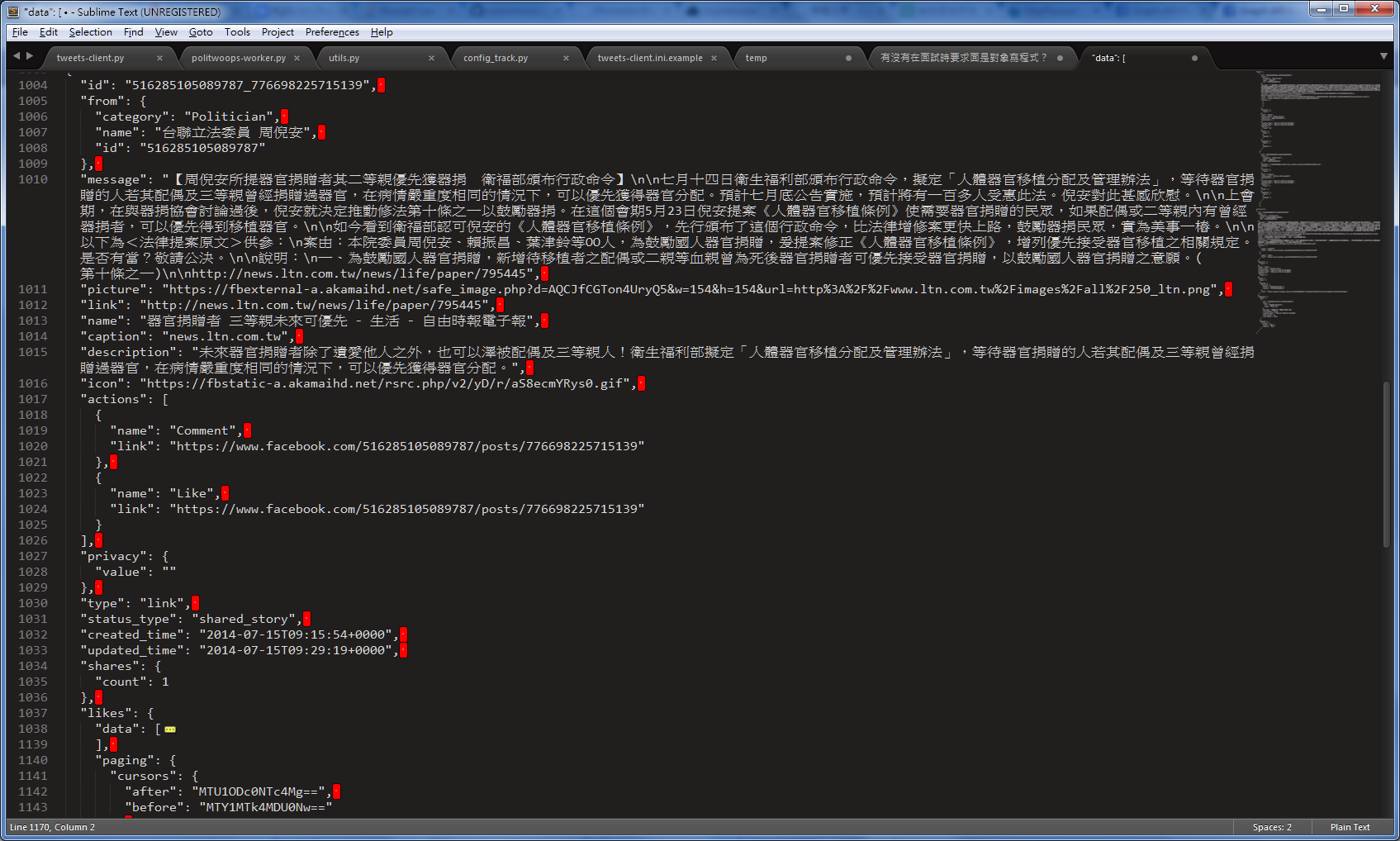
feed's uni link 可以在 actions: 裡面找到 ( comment & like )。 ( for deleted)
周倪安這篇改了四次,但在抓下來的資料裡面只有 create_time 跟 updated_time 能看出明顯的差異... (for edited)
- FB api 可以用 since, until (Unix timestamp格式)去抓時間區間的feeds,但這只限於created_time。
updated_time 可能還是得一個一個比對...=_= post feed 感覺就是免洗啊 囧...
API差異
- 沒有 edit 功能
- API有提供轉推(retweet)的資訊
- 有edit 功能,但 API 不提供比對
- 沒有獨立提供 shared via 的資訊
"retweet_status' = False || { entities }
本來打算用 updated_time 做 compare, 但原 feed 就算內容沒變,有人 like or comment 也會更新 updated_time...
但可用 feed 內的 type, status_type, link 做比對(通常是 shared_story + [type] + link
- all feed keys: id, from, actions, type, privacy, created_time, updated_time, status_type, shares, likes, comments, picture, message, link, application, name, properties, object_id, place, caption, description, story, icon, source
- must have's feed keys: id, from, actions, type, privacy, created_time, updated_time
- type = ['status', 'link', 'video', 'photo']
- status_type = ['mobile_status_update', 'created_note', 'added_photos', 'added_video', 'shared_story', 'created_group', 'created_event', 'wall_post', 'app_created_story', 'published_story', 'tagged_in_photo', 'approved_friend']
talks
依目前 (7/15) 看 code 的狀況, 2 & 3 應該會混在一起做;如果有類似 tweepy 的 FB library 則應該會在 8 月初前完成,沒有的話可能得自幹類似 tweepy 的 library.... 那在 8/20 前會完成 ( 後端能做 demo
那這禮拜的進度就是先玩一下facebook oauth 和facebook api?
玩 fb api ing LOL
應該要申請一個faebook app,拿到app id跟app key之後,在app裡面填上去,根據facebook 的oauth流程,可以拿到user的access token,不過public posts應該不用這樣? XD
我先從 graph API Explorer 做測試XD 但我的牆實在是太髒了lol...感覺要申請一個空帳號來抓會比較好明白會出哪些data
ya, 申請一個空帳號,另外也可以看能不能抓到某個政治人物facebook的public posts
https://developers.facebook.com/docs/public_feed 另外這邊好像有ˋ提到delete的東西參考一下
! ok我去研究看看XD
#1
測試用的機器是跑 Lubuntu 12 & 14,
dependencies 包括: git, python, pip, pythonsqldb, mysql, beanstalkd, tweepy(新版) 跟原project requirements 內的python相關套件。
pip在 lubuntu 下要用 easy_install 安裝,直接用 apt-get 到後面會炸掉...(原因不明)
照 README.md 跑到 Running 前, config 檔寫好之後 create database,資料表的部份因為相依在前端的project,這邊先用 ly提供的 sql schema ,倒進 databse 。
切進 politicians tables, 加入測試用的 twitter_id & infos.
跑 Running. (( 第三支截圖用的不跑,config中用 # 把 [AWS] 下的設定都註解掉
#2
DO 機器是 Ubuntu 12.04(LTS)
feeds 可以抓到一些很奇妙的東西....像是某擬參選人去open groups like post, comment 別人的 post 之類的....(但用 api 沒辦法直接抓到那則post 的 feed)
為了避免漏抓 feed, streaming 改成 now() - 10min. ((也就是說 -client start 的時候會先讀前 10分鐘的內容
這樣子的好處是, streaming 的間隔是 1min (目前),每次 on_data() 的情況都會是前 10分鐘~現在,feed 如果存在的話就會被抓到10次。 ((剛好可以拿來 check edited.
((↑↑↑↑不知為何覺得寫得好像有點難懂XDDDD 想到要做 ppt 可能要畫圖就覺得有點痛苦 囧...
另外因為 deleted_feed 也會對存在 feeds table 裡面的 feed 做 check, 所以剛好可以解決 feed be edited 的問題(時間差)。